El Otro Perú es un proyecto periodístico que visibiliza el impacto de la pandemia de covid-19 en los pueblos indígenas de la Amazonía peruana. El resultado —una plataforma digital que combina gráficos interactivos y reportajes— evidencia el papel que puede jugar el análisis de datos en una cobertura a profundidad. Evidencia también la utilidad de mecanismos de transparencia previstos en la legislación, como las solicitudes de acceso a la información pública, para cerrar las brechas informativas que ahondan el aislamiento de las poblaciones originarias.
El proyecto construyó y analizó bases de datos con información de diversas fuentes confiables para elaborar una radiografía completa de la situación de las comunidades nativas de cinco regiones o departamentos del país: Amazonas, Loreto, Madre de Dios, San Martín y Ucayali.
Dichas regiones fueron escogidas por ubicarse íntegramente en el ámbito de la Amazonía y por presentar un porcentaje significativo de población indígena. Sin embargo, el proyecto se expandió posteriormente hacia otras regiones con presencia de localidades indígenas amazónicas como Cusco, Huánuco y Junín, de acuerdo con el registro de pueblos originarios del Ministerio de Cultura del Perú (Mincul).

Una mirada a profundidad
A través de mapas, gráficos estadísticos y otras visualizaciones, la plataforma muestra distintas capas de información relevante para comprender las condiciones en que viven las comunidades nativas en el contexto de la pandemia, un tema que en general está ausente de la agenda de los medios tradicionales, abocados a cubrir la emergencia sanitaria desde las ciudades.
En primer lugar, este especial permite consultar, a nivel de distritos, la ubicación de los centros poblados habitados por los diversos grupos étnicos amazónicos. Esta información cartográfica es acompañada por la ubicación de los establecimientos de salud de diferente rango en cada distrito, además de datos demográficos, económicos y sociales, lo que incluye, por ejemplo, el acceso a servicios básicos.
En segundo lugar, hace posible monitorear el avance del proceso de vacunación contra la covid-19 entre la población nativa de cada distrito. En tercer lugar, examina la incidencia de enfermedades infecciosas endémicas en la Amazonía peruana: dengue, zika, chikungunya y malaria. Por último, precisa el número de contagios y de fallecidos a causa de la pandemia por pueblos indígenas y por distrito.
Información a cuentagotas
El trabajo se inició con la recopilación de los datos, una etapa difícil por la falta de información de parte de las fuentes oficiales: al principio la variable étnica no estuvo contemplada en el abordaje sanitario y luego, cuando ello empezó a corregirse, no se puso a disposición de la ciudadanía datos abiertos sobre el tema. “El Ministerio de Salud no tenía (datos) históricos de la vacunación en los pueblos indígenas”, comenta Jason Martínez, jefe de Tecnología y cofundador de Salud con Lupa.
José Luis Huacles, periodista de datos de Salud con Lupa, cuenta que, para obtener los indicadores que se necesitaba, se enviaron varias solicitudes de acceso a la información al Ministerio de Salud (Minsa). Dichas peticiones son un procedimiento contemplado en la Ley de Transparencia y Acceso a la Información Pública, promulgada en 2002, que obliga a las entidades del Estado a proporcionar a los ciudadanos la información que requieran y que no tenga carácter de reservada.
Las respuestas obtenidas fueron insatisfactorias. Acerca de la vacunación, el Minsa contestó que no contaba con un plan específico para las comunidades nativas. Respecto a otros asuntos, el ministerio sugirió consultar a las autoridades regionales o revisar la llamada Sala Situacional Indígena, una plataforma web creada por el gobierno nacional en la que se presentan visualizaciones sobre el número de casos y fallecidos a causa del covid-19 por etnia, por circunscripción geográfica y por comunidad. Sin embargo, esa plataforma no permite descargar los datos “crudos” y, en ciertos casos, presenta información incompleta.
Se enviaron también solicitudes de acceso a la información a las direcciones regionales de salud (Diresa), organismos descentralizados que dependen de los gobiernos regionales. Se intentó contactar a las Diresa de las cinco regiones priorizadas, pero una vez más se encontraron barreras. En ninguno de sus sitios web, se incluía el formulario para esta clase de solicitudes ni el nombre del responsable de gestionarlas. El problema se repetía en los sitios de los gobiernos regionales. El gobierno de Amazonas recibió la solicitud pero nunca respondió. Al final, solo se obtuvieron respuestas de dos de regiones: Ucayali y San Martín, las cuales proporcionaron información sobre número de contagios y fallecidos. Ambas habían tomado la previsión de registrar el grupo étnico en sus estadísticas respecto a la covid-19.
Cruce de datos
Según explica Jason Martínez, se decidió analizar los datos a nivel distrital, un espacio en el que se podía ubicar a las localidades indígenas, en vez de organizar la información por comunidades nativas. Para ello, hizo falta cruzar bases de datos de diversas entidades. Al Ministerio de Cultura (Mincul) se le pidió, por medio de una solicitud de acceso a la información, la base de datos de la población originaria, ya que existía información en su web pero no estaba actualizada. Se consiguió así la relación y la ubicación georreferenciada de centros poblados indígenas. La información incluía datos sobre la cobertura de servicios básicos como agua, desagüe y electricidad.
También se tocó la puerta del Ministerio de Desarrollo e Inclusión Social (Midis). Este ministerio cuenta con una plataforma digital que muestra, a nivel distrital, el porcentaje de viviendas con acceso a servicios básicos y el porcentaje de menores vacunados de acuerdo con el esquema básico de inmunización, entre otros indicadores. A través de una solicitud de acceso a la información, se pidió permiso para ingresar a componentes de la herramienta que normalmente no están disponibles para el público a fin de poder descargar datos y aplicar distintos filtros. El acceso fue concedido.
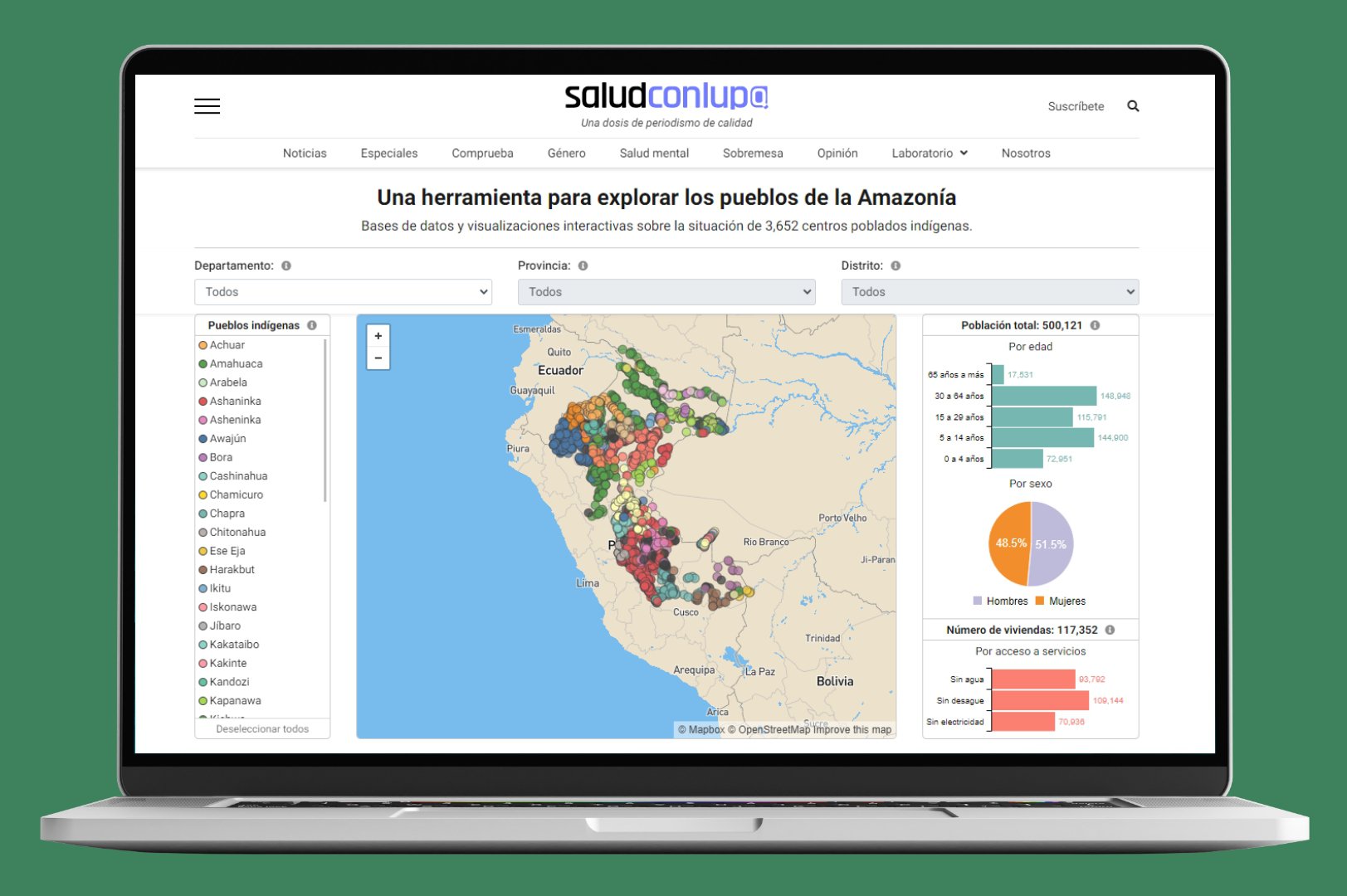
Adicionalmente, se consultó el Registro Nacional de Instituciones Prestadoras de Servicios de Salud (Renipress), una base de datos de la Superintendencia Nacional de Salud (SuSalud). Se trata de un buscador abierto al público, que contiene datos georreferenciados de todos los establecimientos de salud del país, sean públicos o privados, organizados por categorías y por territorios (departamentos, provincias y distritos). De igual modo, se consultó el Registro Nacional del Personal de la Salud (INFORHUS). Con ese cruce de información, se pudo determinar cuántas personas trabajan en cada establecimiento y de qué profesión son. La mayoría de comunidades amazónicas solo tienen acceso a establecimientos de categoría I-1 (puesto, posta de salud o consultorio con profesionales de salud no médicos) y I-2 (puesto o posta de salud con médico).
Además, se examinó información del Instituto Nacional de Estadística e Informática (INEI); en concreto, el Censo de Comunidades Nativas 2017, que sirve como fuente para una parte de los datos del Ministerio de Cultura. El censo permite aproximarse a las condiciones socioeconómicas de la población indígena e incluye otros datos relevantes como el nivel educativo y la lengua.
Como se optó por trabajar con datos georreferenciados y se había previsto elaborar mapas interactivos para presentarlos, se contrastó la información sobre las demarcaciones territoriales con la relación de ubigeos que maneja el Registro Nacional de Identidad y Estado Civil (Reniec). El ubigeo —acrónimo de “ubicación geográfica”— es un código establecido por el Estado Peruano para identificar de forma precisa cada circunscripción.
Procesamiento y desarrollo
Esas bases de datos pasaron primero por un proceso de limpieza y estandarización para el cual se usó el software OpenRefine. Ello permitió que toda la información se guardara en archivos de formato CSV, el cual facilita su tabulación.
Para el procesamiento, el análisis y el cruce de las bases de datos se trabajó en la plataforma Jupyter Lab, la cual emplea el lenguaje de programación Python, explica Martínez. Esta hace posible crear secuencias para automatizar el procesamiento de la información. Junto con Jupyter Lab, se utilizaron las librerías Pandas, Numpy y Matplotlib para la exploración y transformación de datos. Como se sabe, una librería es un conjunto de scripts o líneas de código que pueden reutilizarse para realizar ciertas tareas.
Todo ello desembocó en el desarrollo de la plataforma web descrita antes, en la que se puede navegar en un mapa y explorar visualizaciones de las diferentes bases de datos mediante filtros por departamento, provincia y distritos. Elaboramos dichas visualizaciones recurriendo a librerías de JavaScript como D3.js y Leaflet.js.
El resultado es una herramienta potente y amigable que contribuye a la comprensión de los desafíos que enfrentan hoy las comunidades indígenas en la Amazonía peruana. Dicha herramienta, que se publica acompañada de diversas piezas periodísticas, constituye un aporte no solo para la labor de los investigadores interesados en este sector de la población del país, tantas veces olvidado, sino sobre todo para la toma de decisiones. Con un conocimiento más preciso y completo, se pueden diseñar mejores políticas públicas.